Introduction to Programming with gdeltr2
 Alex Bresler
Alex BreslerPurpose of this Tutorial
I have 2 goals that I hope everyone who takes the time to read this tutorial comes away with.
GDELT is the Coolest Tool You Probably Never Heard Of
The The Global Database of Events, Language, and Tone [GDELT] is an absolutely incredible tool that monitors the world’s information.
It tracks millions of websites from around the world in real-time to extract information and make it machine readable. It also uses advanced machine learning tools like Google Cloud Vision to extract knowledge and predictions from any interactive media content and its various APIs perform a bunch of extremely useful analysis for every article it ingests.
To put it simply, if you monitor information or seek out knowledge GDELT is an extremely powerful and useful weapon.
Anyone with with the Desire to Program Can
The other reason for this tutorial is to show anyone has what it takes to learn how to program. Whether it is my 91 year-old information loving grandmother, my friends in the real estate and finance trying to learn to automate parts of their jobs or my friends in the media trying to get a better grip on what going on in the world via computers, with a bit of desire, patience, a computer and access to the internet you can start programming.
I am optimistic that my gdeltr2 package will be useful enough for the masses that it may provide a springboard to going down the path of really learning how to proficiently program or at a minimum making gdeltr2’s GDELT V2 Full Text API a tool you know how to use when you need it.
So with that, let’s get started.
The Prerequisites
Before we get started with the programming portion of the materials I want to ensure that you have the software and packages needed to complete the tutorial installed.
Please follow these instructions if you don’t already have the software and R packages needed to run gdeltr2.
Step 1: Download R
In order to use gdeltr2 you need the R programming language installed on your computer. Go here and download R for the operating system you are using, make sure to download R 3.4.1.
Step 2: Download RStudio
Once you have installed R I HIGHLY recommend you download the absolutely fantastic RStudio IDE. RStudio is fantastic and one of the top reasons to choose R as your programming language of choice. It makes working with R a breeze and provides a bunch of cool features.
You can install either the stable build or if you want to get adventurous the beta build.
Step 3: Install the gdeltr2 Package Dependencies
R uses a package system. A package contains a bunch of code performs various tasks. In the case of gdeltr2 my package speaks to GDELT’s various APIs. The package brings and munges the data and performs out-of-the box data visualizations.
Once you have installed R and RStudio fire up RStudio and create a new R script file to begin coding.

In order to execute code you need to highlight the line and if you are on a Mac you can run the code by holding command and pressing enter.
install.packages("devtools")
install.packages("purrr")
install.packages("hrbrthemes")
install.packages("tidyverse")
install.packages("plotly")
library(purrr)
packages_to_install <- c("purrrlyr", "wordcloud2", "readr", "tidyr", "ggplot2",
"tibble", "ggthemes", "jsonlite", "dplyr", "rlang", "tidyr", "stringr",
"lubridate")
purrr::map(packages_to_install, install.packages)
Next we have to install the packages that are only hosted on github.
If you successfully installed the packages from CRAN you may need to restart R so it will find the new packages. To do that you can follow this:

devtools::install_github("hafen/trelliscopejs")
devtools::install_github("jbkunst/highcharter")Step 4: Install gdeltr2
Now we can install gdeltr2 from github.
devtools::install_github("abresler/gdeltr2")2 Minute Programming ins R Crash Course
While an in-depth programming tutorial is outside the scope of this tutorial there are a few REALLY important concepts I want to ensure everyone reading this tutorial comes away with.
Some proficiency in these programming concepts are also needed fully harness the gdeltr2’s capabilities.
#1: Treat Text As Strings
This concept may seem a bit strange at first especially if you are completely new to programming.
Try to think about it like this. A computer doesn’t know how to process text by itself. It needs to be told that something is text. The way that is generally done in most programming languages is by wrapping your text in quotes. For the most part {I will discuss this in further detail a bit later}, it doesn’t matter whether you use single quotes or double quotes "My Text" is the same as 'My Text'. In fact let’s test this by asking R to tell us if they are equivalent.
"My Text" == 'My Text'## [1] TRUENotice that if we change the case R will tell us they are no longer equivalent. This is because in R strings are case sensitive.
"My Text" == 'my text'## [1] FALSESo remember when working with text in R or any programming language treat it as a string by wrapping the text with quotes!
#2: Objects
The concept of an object is extremely important any program language. It lets you store things of all varieties. The details what encompasses things is outside the scope of this tutorial but there are a few important things to remember.
Objects, unlike strings NEVER use quotes. In fact, in R if you try to store objects surrounded by quotes they will get stripped.
Objects should also NEVER contain spaces.
Computers have a really hard time understanding the concept of a space. When speaking to a computer if you want to use a space replace the space with _.
With regards to object creation there are are 2 general schools of thought. camelCase which combines upper and lower case text in-lieu of spacing and its rival snake_case which uses the underscore in-lieu of the space. I have no preference for one of the other and I often use both, just remember when creating an object you cannot use a space as part of its name.
Finally you need to store the objects.
R has 3 ways you can do that using either: =, ->, or <- or in a real world example:
object = "my object", "my object" -> object and finally object <- "my object".
I highly recommend using the <- for assignment. I also like to make sure that the code starts on a new line just to make it clear to the eye the name of the object and where the code start.
Let’s quickly demonstrate how to create an object containing some information about my favorite NBA team and player
my_favorite_team <-
"Brooklyn Nets"
favoriteNBAPlayerEver <-
"Mitch Richmond"my_favorite_team## [1] "Brooklyn Nets"favoriteNBAPlayerEver## [1] "Mitch Richmond"#3: The Power of c()
In R c() is one of the most important functions.
According to its documentation the c function stands for combine values into a vector or list which I like to translate into the concept of a container.
When using c() you are creating a container of information that container is also called a vector. The vector has to be all of the same type, if that is not the case R will automatically convert the information contained in c() to be the same type.
Lets quickly go over a practical example that demonstrates my family.
my_family <-
c("Alex", "Liz", "Chase", "Theo")
their_type <-
c("Adult", "Adult", "Toy Poodle", "Baby")
their_age <-
c(33, 32, 2, 0)
Lets print each object to make sure it worked.
my_family## [1] "Alex" "Liz" "Chase" "Theo"their_type## [1] "Adult" "Adult" "Toy Poodle" "Baby"their_age## [1] 33 32 2 0Object vectors can also be be combined. Notice what happens when we combine all the objects we created.
all_objects <- c(my_family, their_type, their_age)all_objects## [1] "Alex" "Liz" "Chase" "Theo" "Adult"
## [6] "Adult" "Toy Poodle" "Baby" "33" "32"
## [11] "2" "0"#4: Data Frames
While I am not going to use data frame’s explicitly in the upcoming tutorial its concept is important and powerful enough I wanted to briefly discuss what they are.
A data frame is essentially a spreadsheet without the BS. Each column of the data frame requires a name and the values contain vectors of the same length and type.
They look and feel like the spreadsheets most of us know and love/hate except in the data frame you there is no formatting, you can’t mess around with comments, combine cells, and all the the types have to match which, believe it or not forces you to think about how to construct clean, easy to use and share data.
R comes built in with a function called data.frame(), there is another more souped up that you can find in the dplyr package that I always use called data_frame(). It is significantly faster and does a bunch of things behind the scenes that I find far superior to the built in data.frame function.
Using the objects about my family from above lets quickly demonstrate how to build a data frame.
library(dplyr)
df_bresler_family <-
data_frame(name = my_family, type = their_type, age = their_age)df_bresler_family## # A tibble: 4 x 3
## name type age
## <chr> <chr> <dbl>
## 1 Alex Adult 33.0
## 2 Liz Adult 32.0
## 3 Chase "Toy Poodle" 2.00
## 4 Theo Baby 0
Where to Learn More
There are a bunch of great resources to go deep into learning how to program in R.
The one I recommend most is Hadley Wickham and Garrett Grolemund’s R For Data Science. Other good resources include R-Bloggers and Weekly
Now on to the exciting stuff.
Interact with the the GDELT V2 Full Text API via gdeltr2
This newly released API provides streaming access to a whole host of GDELTs coolest features.
In this section I am going to walk through a bunch of the API search parameters that will allow us to generate our own interactive trelliscopes to help us understand what is going on in the world.
To do this, I am going to walk through the majority of the parameters of the workhorse function get_data_ft_v2_api which accesses data from GDELT and builds various interactive visualizations depending on the type of results you want.
I encourage everyone who wants to fully understand what the V2 API can do and how my function works to take a look at this FT V2 API documentation from GDELT and the function documentation gdeltr2 in the code ?gdeltr2::get_data_ft_v2_api().
Load gdeltr2
Now it is time to load the package.
library(gdeltr2)Terms
What Is It
This parameter lets you search GDELT’s entire Full Text API for up to the last 3 months for ANY term your heart desires.
This can be a person, place, thing, name, phrase, literally ANYTHING you can imagine and when you think about the fact that GDELT monitors millions of websites from around the world every second you quickly realize that you can use this to find some truly obscure information.
How It Works
GDELT indexes and sucks in all the text from page it processes. The V2 Full Text API lets users search through this text and if there is a match returns any matches.
Tidbits to Remember
If you want to find exact terms you need to use a quoted string.
To GDELT if you search for "Brooklyn Nets" it will go through every article and return anything that contains the words Brooklyn AND Nets. The words don’t have to be next to each other to return a positive match.
For example, if there was an article in a publication that discussed a fundraiser in Brooklyn that nets a large donation from an unknown benefactor it would return this as a match. This is not something I want to see if I am only looking for articles about my favorite NBA team the Brooklyn Nets. To find those matches I want want to search '"Brookyln Nets"'.
In some cases this won’t matter too much, but depending on the terms you are looking for it may.
You can also combine phrases like '"Brooklyn Nets" playoffs' which would search for “Brooklyn Nets” AND the word playoffs or '"New York City" "City Council"' which would look for “New York City” AND City Council.
Example: Terms to Search
Now that we have covered what this parameter is lets build a vector of terms to use for our analysis
sports_terms <-
c('"Brooklyn Nets"', "Caris LeVert", '"Kyrie Irving" Trade', '"Luka Doncic"',
'NBA "Draft Prospect"', '"Jarrett Allen"')
political_terms <-
c('"Bill Perkins"', '"New York City" "City Counsel"')
finance_real_estate_terms <-
c("Eastdil", "Condo Bubble", '"JBG Smith"', '"CPPIB"', "Anbang",
"WeWork", '"Goldman Sachs"' , 'Blackstone "Real Estate"')
other_terms <-
c("Supergoop", '"LNG"', 'Maryland "High School Football"',
'"Jared Kushner"', '"Eddie Huang"')
my_terms <-
c(sports_terms, political_terms, finance_real_estate_terms, other_terms)Domains
What Is It
Indexing and parsing web-domains is the lifeblood of GDELT. If there is a website you read that publishes information the odds are it is tracked by GDELT.
The V2 Full Text API lets you provide a set of web domains and if they are indexed by GDELT it will return the articles it indexed over the user specified time period.
This parameter makes GDELT an easy way to continuously keep track of the websites you enjoy reading.
How It Works
Each second GDELT scours millions of websites from around the world for new content. When a new article is discovered the contents of the article get processed through GDELT’s APIs.
The APIs do a variety of things from extracting out numeric references, people, places, to generating sentiment scores. They even extract out media content and process the videos and photos through all of Google Cloud Vision’s APIs which can do everything from identifying what is in the photo, to predicting the sentiment of the any person in the photo, they even attempt to identify whether the photo contains a brand!
Tidbits to Remember
Don’t use http:// or https:// when searching for domains.
Remember to use the type of website that it is ie don’t search espn if you are looking for espn.com
Example: Domains to Search
Now lets build a vector of some of the domains I enjoy from various aspects of what I like to monitor in the world.
news_domains <-
c("nypost.com", "washingtonpost.com", "wsj.com", "gothamgazette.com")
sports_domains <-
c("espn.com", "netsdaily.com")
finance_real_estate_domains <-
c("realdeal.com", "zerohedge.com", "institutionalinvestor.com", 'pionline.com',
"curbed.com", "archdaily.com")
random_domains <-
c("tmz.com", "snopes.com", "alphr.com", "oilprice.com")
my_domains <-
c(news_domains, sports_domains, finance_real_estate_domains, random_domains)Global Knowledge Graph [GKG] Themes
What Is It
This is one of my favorite features!!
GDELT has created a list of nearly 21,000 themes it actively seeks to tag whenever it process an article.
Some of the themes are taken from other organizations like the World Bank while others internally developed. The themes cover just about every imaginable topic in world affairs. They range from obscurities like dandruff to outlandish topics like perverted actions to serious topics like drug overdoses.
They track economic events, political events, scientific events, corporate actions, just to name a few categories!
How It Works
Every time GDELT processes new content it performs Natural Language Processing [NLP] on the text.
As part of this they use the processed text assign any number of themes to the article.
For example if GDELT reads in an article and processes text to find the phrase “white stuff falling to the ground from the man’s head from a dry scalp” it would assign the GKG theme corresponding to dandruff from above.
One article can have many themes as well.
Exploring in Detail
Given the shear volume and power of these GKG themes I encourage everyone to spend some time perusing the themes to identify those that may be of interest in your every day quest for staying on top of world affairs.
You can interactively explore the active GKG themes as of this post here or explore GKG themes in R with the following code:
df_gkg <-
get_gdelt_codebook_ft_api(code_book = "gkg")
View(df_gkg)Tidbits to Remember
When entering in a theme you must be exact.
If you were looking for articles about dandruff you must enter the exact code of "TAX_DISEASE_DANDRUFF". The codes are not case sensitive "tax_disease_dandruff" or Tax_Disease_Dandruff would also work.
Example: Themes to Find
In this example in addition to the themes I specifically define, I am going to include 3 additional random themes.
The reason you will see the set.seed function is to ensure that your random 3 themes are the same as mine.
Here is how we define them:
df_gkg <-
gdeltr2::get_gdelt_codebook_ft_api(code_book = "gkg")
my_themes <-
c("ECON_WORLDCURRENCIES_CHINESE_YUAN", # stories about china's currency -- god way to find stories about china's economy
"ECON_BUBBLE", # articles about economic bubble
"TAX_FNCACT_BROKER", # articles about brokers of things
"ECON_HOUSING_PRICES", # articls about housing prices
"ECON_BITCOIN", # articles about bitcoin
"ELECTION_FRAUD", # articles about election fraud
"SOC_POINTSOFINTEREST_GOVERNMENT_BUILDINGS", # articles about government buildings
"WB_1277_BANKRUPTCY_AND_LIQUIDATION", # articles about bankruptcy
"WB_639_REPRODUCTIVE_MATERNAL_AND_CHILD_HEALTH", # articles about pregnancy and child health
"WB_2151_CHILD_DEVELOPMENT", # articles about child development
"TAX_FNCACT_BUILDER" # articles about builders
)
set.seed(1234)
random_themes <-
df_gkg %>% pull(idGKGTheme) %>% sample(3)
my_themes <-
c(my_themes, random_themes)Optical Character Recognition [OCR]
What Is It
This parameter enables you use GDELT to search for text extracted from media content.
This is a great way to keep track of brands and find pictures containing certain text that may be of interest to you.
How It Works
One of the many really cool things Google Cloud Vision does is extract out text from media content.
Since GDELT uses Google Cloud Vision for every website it monitors it takes each piece of media content it finds and uses Google Cloud Visions OCR API to extract out any text it finds.
GDELT’s V2 Full Text API will then let you search through the results for any matching user defined text!
Tidbits to Remember
Consider spelling, abbreviations and logo names. Google’s OCR technology isn’t perfect so there may be some inaccuracy.
Example: Words to OCR
Here we are going to define a vector of some random things I want to look for in photos as part of our analysis.
my_ocr <-
c(
"Brooklyn Nets",
"Panerai",
"Four Seasons",
"NBA",
"Goldman Sachs",
"Philadelphia Eagles",
"Supergoop",
"Boston Celtics",
"Big Baller Brand",
"BBB",
"Boston Properties"
)Exploring in Detail
Similar to the GKG Themes there are a number of imagetags, 8977 as of the time of this post.
I encourage you to spend a bit of time perusing them to help you identify imagetags that may be of interest to you and as before, you can explore the active tags interactively here or in R with the following code:
df_imagetags <-
get_gdelt_codebook_ft_api(code_book = "imagetags")
View(df_imagetags)Tidbits to Remember
Use the specific code without quotes. These are also not case sensitive. The tags also won’t always be accurate.
Exploring in Detail
Similar to the GKG Themes and Imagetags there are a number of imagewebtags, 21,097 as of the time of this post.
It is both fun and useful to spend some time looking at the multitude of people, places, things, concepts, teams, brands, companies, locations and ideas that Google has learned and actively looks for.
You can explore the active tags interactively here or in R by with the following code:
df_imageweb <-
get_gdelt_codebook_ft_api(code_book = "imageweb")
View(df_imageweb)Tidbits to Remember
As is the case with OCR, GKG, and Imagetags don’t use quotes and give the exact term in which ever case you desire. With these I encourage you to monitor them over time as Google is constantly learning new things that you can search for and also remember that Google isn’t always accurate in its predictions.
Other Parameters
The final step before we can run our search and create the interactive trelliscopes is to go over a few other parameters you should be aware of.
#1: Timespan
As I mentioned before, GDELTs V2 Full Text API gives you access to information over continuous 3 month periods.
You can ask the API for information as far back as 12 weeks to as recent as 1 minute ago.
In gdeltr2 you must define time-spans, if you don’t it reverts the default of anything in the last 24 hours.
When defining a timespan it must be given as a string containing either minutes, hours, days, or weeks ie: "24 hours", "97 minutes", "17 days", or "12 weeks".
For our initial example lets define the timespan as anything published within the last 5 days.
my_timespan <-
"5 days"#2 Maximum Records
This parameter defines the maximum amount of results you want to return for any API call with results.
The default and maximum allowed per API call is 250 which at times may mean you aren’t getting the full set of results.
There is a way to circumvent this a bit by defining specific dates instead of time-spans for the time horizon but that is much more complicated and outside the scope of this tutorial. Any advanced user who needs to know more about this can reach out to me directly.
For our example we can leave this parameter empty as we want to use the default of 250 results.
#3 Source Country
This parameter lets you isolate your search to a specific country or countries.
If you don’t enter anything this it will search the whole world and this is the default.
If you wish to isolate a country you must specify the exact country code or codes you want to isolate.
To explore the available country codes you can use the following code:
df_countries <-
get_gdelt_codebook_ft_api(code_book = "countries")
View(df_countries)Again, since we are using the default parameter we don’t need to enter anything.
#4 Trelliscope Parameters
This is an advanced feature that lets the user define some parameters that modify the interactive trelliscope.
They must be passed through as a list containing either: rows, columns, or path.
Rows define the number of rows for the trelliscope. We will use 1.
Columns define the number of columns we want to use, in this case we will use 2.
Finally path, allows you to save and publish your trelliscope if you have access to folders related to a website. In this tutorial we aren’t going to do that so we will set that parameter to NULL.
my_trelliscope_parameters <-
list(
rows = 1,
columns = 2,
path = NULL
)Finally if we were to enter nothing and exclude the my_trelliscope_parameters from our function call it would default to the parameters above.
Creating the Trelliscopes
We are now ready to use the get_data_ft_v2_api function and create our interactive trelliscopes!
The function supports a number of different types of output via its modes parameter.
These options include basic image panels with links to the article, interactive visualization of the amount of activity for the specified search parameter and even various forms of wordclouds for each search parameter!
By default gdeltr2 will create an object in your environment starting with the word trelliscope this makes it easy for you to explore the trelliscope once it has been created.
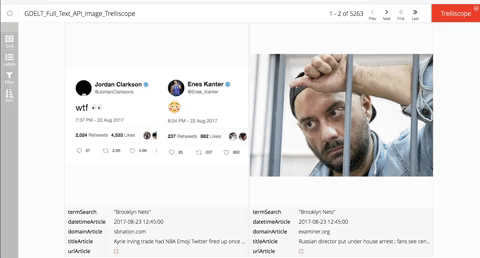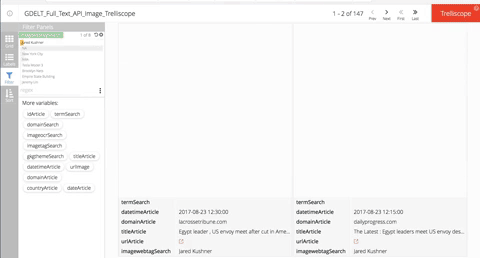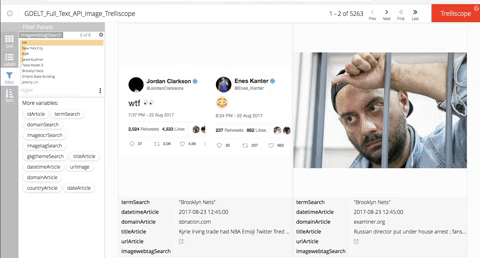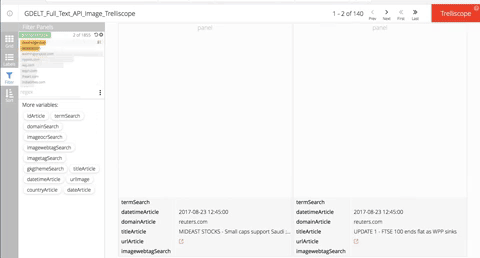
Image Panels
Parameter: modes = 'ArtList'
This is the default parameter and my personal go to for how I interact with GDELT on a daily basis.
In order to create an image panel trelliscope all we do is pass along each of the parameters we defined and in no time you should have an interactive trelliscope with clickable links for your view into the world.
Here is how to do it:
get_data_ft_v2_api(terms = my_terms, domains = my_domains, images_web_tag = my_image_web,
images_tag = my_image_tags, images_ocr = my_ocr, gkg_themes = my_themes,
modes = c("Artlist"), timespans = my_timespan, trelliscope_parameters = my_trelliscope_parameters)trelliscopeImageTimeline Volume
Parameter: modes = "TimelineVolInfo"
This mode will create an interactive chart with the date on the x axis and the volume score on the y axis.
The volume score is essentially how much your specified parameter was mentioned.
In these trelliscopes if you click on the line it will return a tooltip containing clickable links to your specified search parameter.
When using this mode I highly recommend changing the timespan to 12 weeks in order to give you the maximum view on how often your parameter was discussed.
Here is how to create this:
get_data_ft_v2_api(terms = my_terms, domains = my_domains, images_web_tag = my_image_web,
images_tag = my_image_tags, images_ocr = my_ocr, gkg_themes = my_themes,
modes = c("TimelineVolInfo"), timespans = "12 weeks", trelliscope_parameters = my_trelliscope_parameters)trelliscopeHighcharterClick here if you wish to explore in full screen mode
Wordclouds
Parameter: modes = c("WordCloudEnglish", "WordCloudTheme", "WordCloudImageTags", "WordCloudImageWebTags")
These modes allow you to create various wordclouds for each specified search parameter.
WordCloudEnglish returns a word cloud of the most commonly used English words for the specified sarch parameter.
WordCloudTheme returns a wordcloud of the most identified GKG themes.
WordCloudImageTags returns the most commonly found Imagetags and WordCloudImageWebTags returns the most commonly found ImageWebTags.
These wordclouds can be a great way to quickly understand what is going on with regards to specific search parameter.
Here is how we create a trelliscope that displays each of these wordcloud types. For this analysis we are going to slightly modify the panels to only show 1 column and 1 row and we will also expand the time frame to 2 weeks.
get_data_ft_v2_api(terms = my_terms, domains = my_domains, images_web_tag = my_image_web,
images_tag = my_image_tags, images_ocr = my_ocr, gkg_themes = my_themes,
modes = c("WordCloudEnglish", "WordCloudTheme", "WordCloudImageTags", "WordCloudImageWebTags"),
timespans = "2 weeks", trelliscope_parameters = list(rows = 1, columns = 1,
path = NULL))trelliscopeWordcloudInteracting with the Trelliscope
After you execute the code you will notice the trelliscope in your viewer pane. To best interact with the Trelliscope I like to open it in my browser of choice. To do that click the button to the right of the broom button.

If you always want to open interactive content in your browser you can run the following code:
options(viewer = NULL)Shortcuts
You case use the f key to call up all the filters. You can modify the grid by pressing g. You can modify the labels by pressing l. You can change the sorting parameters by pressing s.
Instead of clicking the left and right arrows you can use the left or right keys, or if you are on a mobile device or tablet and it is a trelliscope that lives on the web you can swipe left or right.
Filtering
Searching by Text
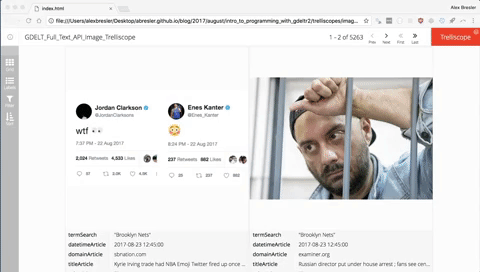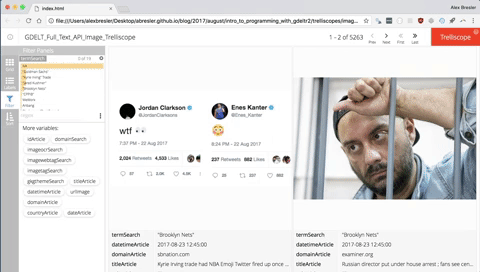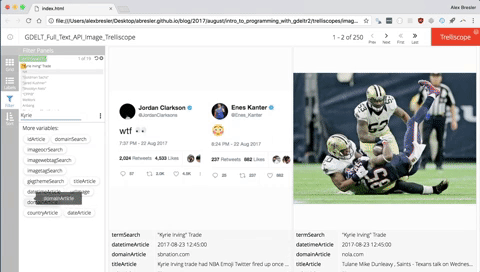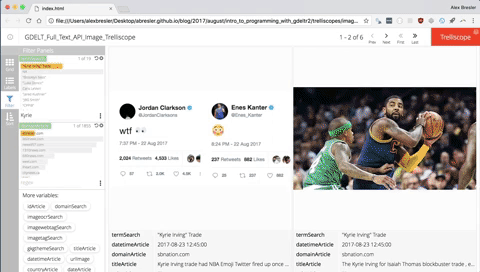
Searching by click
Parting Notes
I hope everyone enjoyed this tutorial and if you made it to the end that you were able to get these trelliscopes showcasing the GDELT V2 Full Text API data up and running on your own computer.
If not, please feel free to reach out to to me and I will try to assist you in getting this to work.
You can access the raw R code here if you want a quick way to try to reproduce the code from this tutorial.
A special thank you to Kalev Leeatru and the entire GDELT team for all the truly remarkable work they have done. I also want to thank Google for their support of GDELT.
A major shout out is owed to Ryan Hafen for his truly beautiful and incredibly powerful trelliscopeJS package. As well as DARPA for funding Ryan and his vision for trelliscopeJS.
This tutorial’s interactive visualizations wouldn’t be possible without the contributions of Joshua Kunst and his work on the wordcloud2 and highcharter packages. Josh you are an all-star!!
I also want to thank Kenton Russell and Ramnath Vaidyanathan for laying the ground work for nearly all the interactive packages that make R such a dynamic programming language with their revolutionary htmlwidgets package.
Remember, GDELT is the coolest thing you now HAVE heard of and you just completed some pretty advanced programming so you cannot say that learning to code is too difficult for you!
Until next time.
